
背景
在深度学习过程中,我们经常会碰到或者听说一些疑问,例如我们在初始化网络的时候,要设置权重和偏置,那么要设置多大呢,等等。非常多的问题,需要我们去验证,并且证明论文和前辈的结论正确。本文就是根据这些疑问,做了不同的实验,竭力证明这些观点的正确或者错误。
本文主要测试了以下几个问题:
- 初始权重(w)、偏置(b)和学习速率的设置对识别率的影响
- 识别率和死神经元(输出为零)之间的关系
- 由于在ReLU网络中,存在大量0神经元(死神经元),是不是可以精简网络
- ReLU和Sigmoid效率简单对比
- Sigmoid网络和ReLU网络识别率差异的问题
- Pre-Train的训练方法学习和实验
- 图片填充后网络识别率的变化
实验
一、权重、偏置和学习速率
实验说明:
权重和偏置设置不同的数值,但是都是取标准误差为0.1~0.9之间任意数值;学习速率设置为0.3~2.7之间任意数,使用mnist数据集,根据不同的迭代次数得到不同组合数据,并形成初步结论。
神经网络说明:
三层网络,输入层为784个神经元,隐藏层共1层,有30个神经元,输出层为10个神经元;输出层使用sigmoid和ReLU作为激活函数
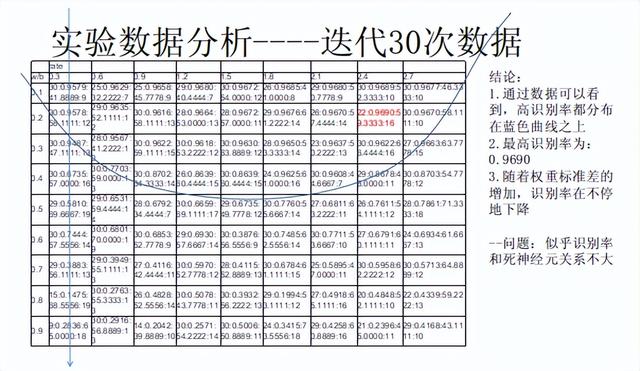
实验一:

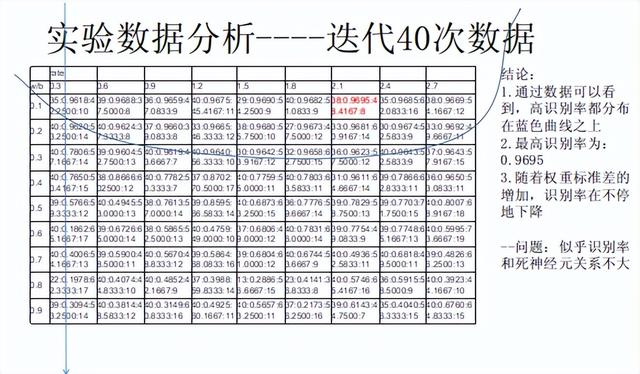
实验二:
实验三:.

实验总结:
- 随着权重的标准差增加,识别率会越来越低。
- 从蓝色曲线看,随着迭代次数的增加,高学习速率下的识别率逐渐覆盖高标准差的权重;
- 随着迭代次数增加,出现的最高识别率的数值也在增加:0.9690(30次)< 0.9695(40次) < 0.9704(50次)
结合上面实验查阅了关于权重初始化的论文:
参考论文一:《Understanding the difficulty of training deep feedforward neural networks》
本论文中有这样一段话:
We find that the logistic sigmoid activationis unsuited for deep networks with random initialization because of its mean value, which can drive especially the top hidden layer into saturation.
通过上面这段话,我们获知这篇论文还是主要讲的是sigmoid网络中的权重初始化,论文结论如下,我们也通过实验进行了验证。
对于激活函数为sigmiod的网络,初始化方法如下:
- 对网络逐层进行Pre-Train
- 在一般情况下可以使用n*Var(W)=1/3进行初始化,n为层的神经元个数(where n is the layer size(assuming all layers of the same size))。
- 如果逐层进行权重初始化,满足如下公式(We call it the normalized initialization):
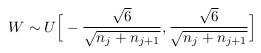
说明:每一层W设置属于U指定的范围,并且跟神经元个数相关
以上就是论文《Understanding the difficulty of training deep feedforward neural networks》的结论,
针对论文的结论,我们验证了sigmoid网络和ReLU网络,发现初始化方法同样适用于ReLU网络。
注:
- 在Sigmoid网络中,需要通过这个初始化理论逐层Pre-Train然后再组合成深层网络才可以。否则隐藏层为2层或以上,识别率就从10%左右起,非常难于训练。
- 我们还发现,对于初始化方法2,即n*Var(W)=1/3, 当隐藏层为8层及以上,即加上输入层和输出层一共为10层及以上的网络的时候,这个初始化对于sigmoid和ReLU网络都会失效。
- 在Tensorflow关于xavier的API中建议:This initializer is designed to keep the scale of the gradients roughly the same in all layers. In uniform distribution this ends up being the range: x = sqrt(6. / (in + out)); [-x, x] and for normal distribution a standard deviation of sqrt(2. / (in + out)) is used。我们可以看到当使用random_normal初始化权重的时候,和Xaviver论文中提到的略有不同。
- 在Tensorflow API中,对于一般的初始化方法,在版本1.0中使用的是sqrt(3./(in + out))作为权重的初始化参数,在注意事项3中sqrt(2./(in + out))出现在tensoflow api 1.3中.
参考论文二:《Surpassing Human-Level Performance on ImageNet Classification》
本论文主要是讲述的CNN网络的初始化,论文是通过两个Cases完成了推导:
- Forward Propagation Case
- Backward Propagation Case
结论:
在Forward Propagation Case中,通过推导得出如下公式:
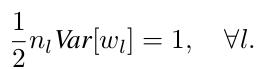
其中,下标“l”为神经网络层级,输入层l = 1,其他层为l = l;n = k*k*c, k为当前层spatial filter的大小,c为channel数量. 此时依然设置偏置b = 0
注:
论文中特别强调,当在input层,即l = 1时,存在n1Var[w1] = 1, 和结论公式不符合。事实上即便input层使用通用公式来设置也问题不大。
在Backward Propagation Case中,通过推导得出如下公式:
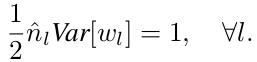
其中,下标“l”为神经网络层级,n^ = k*k*d, k为当前层spatial filter的大小, d为channel数量,且和Forward Propagation Case中的c比较,存在c(l) = d(l-1)
根据上面2个case总结的公式,我们可以看出,我们单独使用其中一个公式是完全可以的,这个在论文中也提到了。
二、ReLU和Sigmoid(Tanh)效率
在阅读论文《ImageNet Classification with Deep Convolutional Neural Networks》的时候,有如下结论和配图:

论文中说明:A four-layer convolutional neural network with ReLU(solid line) reaches a 25% trainning error rate on CIFAR-10 six times faster than an equivalent network with tanh neurons(dashed line)
实验四:
实验说明:
这里我们使用一个三层网络,输入层、隐藏层和输出层,神经元个数分别为784、784、10,激活函数分别为ReLU和Sigmoid。由于只是个验证实验,并没有调出识别率最大值,只是以98%的识别率为终点
实验数据:
Sigmoid网络:
|
epoch |
Sigmoid |
epoch |
Sigmoid |
epoch |
Sigmoid |
|
1 |
0.8645 |
21 |
0.971 |
41 |
0.9786 |
|
2 |
0.9002 |
22 |
0.9703 |
42 |
0.9785 |
|
3 |
0.9136 |
23 |
0.9721 |
43 |
0.9786 |
|
4 |
0.9223 |
24 |
0.9704 |
44 |
0.9782 |
|
5 |
0.9292 |
25 |
0.9723 |
45 |
0.9788 |
|
6 |
0.9318 |
26 |
0.9739 |
46 |
0.9793 |
|
7 |
0.9391 |
27 |
0.9734 |
47 |
0.9785 |
|
8 |
0.9426 |
28 |
0.9741 |
48 |
0.9785 |
|
9 |
0.9458 |
29 |
0.9746 |
49 |
0.9793 |
|
10 |
0.9478 |
30 |
0.9755 |
50 |
0.98 |
|
11 |
0.9522 |
31 |
0.9745 |
||
|
12 |
0.9552 |
32 |
0.976 |
||
|
13 |
0.9559 |
33 |
0.9761 |
||
|
14 |
0.9594 |
34 |
0.9762 |
||
|
15 |
0.9626 |
35 |
0.9764 |
||
|
16 |
0.9634 |
36 |
0.9767 |
||
|
17 |
0.9645 |
37 |
0.9777 |
||
|
18 |
0.9668 |
38 |
0.9767 |
||
|
19 |
0.9683 |
39 |
0.9775 |
||
|
20 |
0.9678 |
40 |
0.9782 |
ReLU网络:
|
epoch |
ReLU |
|
1 |
0.9461 |
|
2 |
0.9628 |
|
3 |
0.9699 |
|
4 |
0.9742 |
|
5 |
0.9751 |
|
6 |
0.9761 |
|
7 |
0.9789 |
|
8 |
0.9806 |
|
9 |
0.9799 |
通过以上数据我们绘制 Accuracy vs Epoch
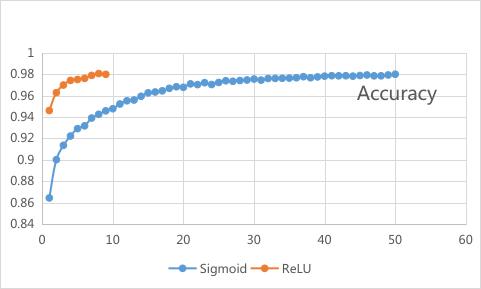
从上图得知,确实在ReLU网络中,可以更快的达到较高识别率,这里ReLU的效率是Sigmoid网络的5倍以上,接近论文中说得在CNN网络中的6倍左右。
结论:在使用同样的初始化参数的情况下,达到相同识别率,ReLU网络需要的迭代次数大约是Sigmoid网络所需迭代次数的1/6~1/5,所以ReLU效率更高, 也就是5~6倍于sigmiod及tanh类的网络。
- Sigmoid和ReLU识别率是否存在差异
在做神经网络的测试的时候,我们会产生如下疑问:
- 为什么不做Pre-train的ReLU网络识别率会比Sigmoid网络高?
- 为什么各种说法说关于识别率ReLU网络并不优于Sigmoid网络?
通过多方验证和实验,答案如下:
- ReLU由于是max(0,x), 即在输出<0的时候,会强制输出0,这样就使得ReLU网络就有了天然的稀疏性,所以训练速度会比Sigmoid网络快很多,如果迭代不充分,就会给人ReLU网络比Sigmoid网络的识别率高;
- 为了减少Sigmoid网络训练的复杂度,达到较高的识别率,一般需要Pre-train,在这样的精心调优下,Sigmoid和ReLU网络的识别率会相当,识别率相当。
- 通过实验四可知,ReLU网络的训练速度是Sigmoid网络训练速度的6倍左右。
四、填充
我们在进行运营过程中,经常会出现对于图片或者文字的整理。例如对于图片不够我们指定的大小时,需要拉伸或者直接填充,以达到我们需要的input神经元个数。
填充实验主要是使用的mnist数据集,mnist数据集中图片灰度最大值为1,最小值为0.
在不做扩充填充的时候,识别率为:0.9704
实验五:
实验说明:对于mnist数据进行改造,mnist数据是28*28的图片灰度数据,对于这些数据不变化,把28*28的数据改造成32*32的数据,填充数据为0\0.5\1等三个数据。
实验网络为1024:30:10的三层网络,其中三个数字为每层神经元的个数,激活函数为ReLU,loss函数为二次代价函数。Var(W) = 0.2, 学习速率为2.51,迭代50次
实验结果如下:
|
四周填充 |
结果 |
|
|
训练数据填充值 |
测试数据填充值 |
l_rate: 2.510000, w_bl: 0.200000,epoch: 50 |
|
None |
None |
epoch: 48(50), accuracy: 0.967300 |
|
1 |
1 |
epoch: 43(50), accuracy: 0.899600 |
|
1 |
0 |
epoch: 48(50), accuracy: 0.952000 |
|
0 |
1 |
epoch: 49(50), accuracy: 0.842100 |
|
0 |
0 |
epoch: 46(50), accuracy: 0.964800 |
|
0.5 |
0.5 |
epoch: 35(50), accuracy: 0.968100 |
|
0.5 |
0 |
epoch: 36(50), accuracy: 0.953800 |
|
0.5 |
1 |
epoch: 38(50), accuracy: 0.954300 |
|
0 |
0.5 |
epoch: 50(50), accuracy: 0.939300 |
|
1 |
0.5 |
epoch: 44(50), accuracy: 0.959000 |
实验结论:
当测试数据特征数据信息增多时,会影响获得较高的识别率。
实验六:
实验说明:训练数据和实验数据填充相同的数值。
实验结果如下:
|
训练数据填充值 |
测试数据填充值 |
l_rate: 2.510000, w_b: 0.200000,epoch: 50 |
|
0.1 |
0.1 |
01: 0.920700, 50: 0.966500 |
|
0.2 |
0.2 |
01: 0.917600, 44: 0.968100 |
|
0.3 |
0.3 |
01: 0.909200, 48: 0.964500 |
|
0.4 |
0.4 |
01: 0.911300, 44: 0.963200 |
|
0.5 |
0.5 |
01: 0.919100, 44: 0.962300 |
|
0.6 |
0.6 |
01: 0.911700, 33: 0.967100 |
|
0.7 |
0.7 |
01: 0.905100, 40: 0.961100 |
|
0.8 |
0.8 |
01: 0.908800, 47: 0.965700 |
|
0.9 |
0.9 |
01: 0.899600, 48: 0.960700 |
|
1 |
1 |
01: 0.897700, 43: 0.960700 |
实验结论:
当随着数据填充值越来越接近有效特征的时候,识别率会有一定下降。结论也同样验证了实验五中的结论。
五、数据做有规则变换
在mnist数据集中,数据总是>0的,所以为了验证在所有样本数据分布在[-1, 1]之间的情况,所以要对mnist数据做一些调整,然后观察识别率变化。
实验七:
实验说明:针对mnist数据集,使用y=2x-1的公式变换数据集中所有数据,由于数据集中原来数据是在[0, 1]之间,所以使用2x – 1的方式,就是的数据分不在了[-1, 1]之间。
实验结果如下:
01: 0.906800, 49: 0.956900
实验结论:
在将原来数据集特征分散的情况下,会对识别率造成一定的影响,不过影响不大。
实验八:
实验说明:针对mnist数据集,如果x!=0的情况下,使用y=2x-1的公式变换数据集中所有数据,由于数据集中原来数据是在(0, 1]之间,所以使用2x – 1的方式,就是的数据分不在了[-1, 1]之间.本实验区别于实验七的着重点是非特征值变成了中间值,即特征数据相对增加。
实验结果如下:
01: 0.862300, 14: 0.913100
实验结论:
由于特征数据相对增加,所以识别率相对于实验七下降了,或说明需要更多的迭代或者样本进行学习。
............试读结束............
查阅全文加微信:3231169 如来写作网:gw.rulaixiezuo.com(可搜索其他更多资料) 本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 3231169@qq.com 举报,一经查实,本站将立刻删除。
本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 3231169@qq.com 举报,一经查实,本站将立刻删除。如若转载,请注明出处:https://www.wuxingwenku.com/24308.html


{kind=link}